
Big Navi 그래픽 카드의 출시와 함께 AMD는 마침내 고급 GPU 공간으로 돌아 왔습니다. RDNA 2 설계는 컴퓨팅 및 그래픽 파이프 라인 측면에서 RDNA 1과 거의 유사하지만 Infinity Cache 및 높은 부스트 클럭을 포함 할 수있는 몇 가지 변경 사항이 있습니다 . 이 게시물에서는 Navi GPU가 GCN 아키텍처로 구동되는 기존 Vega 및 Polaris 부품과 어떻게 다른지에 대해 설명합니다.
AMD의 GCN 아키텍처는 거의 10 년 동안 Radeon 그래픽 카드를 지원했습니다. 이 디자인은 강력한 Compute Engine, 하드웨어 스케줄러, 통합 메모리와 같은 강점을 가지고 있었지만 게임에는 그다지 효율적이지 않았습니다. 하드웨어 사용률은 최신 NVIDIA 부품에 비해 상당히 낮았으며, 셰이더 엔진 당 처음 11 개 CU 이후에 스케일링이 급격히 떨어졌으며 전반적으로 GPU 당 64 개 이상의 CU를 사용하는 것은 불가능했습니다.

그 결과 강력한 컴퓨팅 아키텍처를 갖추고 있음에도 불구하고 AMD의 GCN GPU (Vega)는 NVIDIA의 하이 엔드 게임 제품에 계속해서 패배하면서 훨씬 더 높은 전력을 소비했습니다.

RDNA는 GPU 아키텍처이고 Navi는이를 사용하여 구축 된 그래픽 프로세서의 코드 명입니다. 마찬가지로 GCN은 아키텍처 였고 Vega와 Polaris는 코드 명입니다.
Navi 10 및 Navi 14 GPU (Radeon RX 5500 XT, 5600 XT 및 5700 / XT)를 지원하는 1 세대 RDNA 아키텍처는 GCN과 동일한 빌딩 블록을 기반으로합니다. 주소 계산 및 제어를위한 몇 개의 전용 스칼라가있는 벡터 프로세서 흐름, 별도의 컴퓨팅 및 그래픽 파이프 라인이 비동기 적으로 실행됩니다. 스트림 프로세서라고하는 ALU는 연산 능력을 제공하고 명령 프로세서 (ACE와 함께)는 연산 장치 당 워크로드 스케줄링을 처리합니다.
핵심적인 차이점은 RDNA가 더 높은 IPC, 더 낮은 대기 시간 및 더 나은 효율성을 위해 GCN의 기본 구성 요소를 재구성한다는 것입니다. 이것이 Navi의 모든 것입니다. 현저히 적은 하드웨어로 더 많은 일을합니다!
AMD GCN : 강력하지만 활용도가 낮음
AMD의 GCN 그래픽 아키텍처는 컴퓨팅 유닛 당 64 개의 웨이브 프론트 또는 작업 항목 (및 ALU / 코어)으로 구성되었습니다. 이들은 각각 16 개의 ALU (SP)를 포함하는 4 개의 SIMD (다중 데이터 유형에 대한 단일 명령어)로 나뉩니다.

대부분의 사람들이 혼란스러워하는 곳입니다. 예, 스케줄러가 4주기마다 새로운 웨이브 그룹을 발행 할 수 있지만 한 번에 각 컴퓨팅 유닛은 64 개 항목 웨이브 하나가 아닌 4 개의 64 항목 웨이브 에서도 작동합니다 . 불도저와 마찬가지로 목표는 병렬화를 극대화하는 것이 었습니다. 동시에 GCN은 비 순차적 인 아키텍처가 아니 었습니다. 웨이브 프론트 내의 명령은 여전히 주문에 따라 실행되었습니다. 차이점은 CU 또는 SIMD가 사용 가능한 네 가지 웨이브 중 하나로 전환 할 수 있다는 것입니다.
이것이 그다지 효과적이지 않은 이유는 대부분의 게임이 더 짧은 작업 대기열을 사용하기 때문입니다. 그 이유는 4 개의 웨이브 프론트 중 1 ~ 2 개만 실행주기 당 포화 상태이기 때문입니다. 결과적으로 유사한 셰이더 수를 가진 경쟁 NVIDIA GPU는 Super-Scalar 아키텍처 덕분에 훨씬 빨라졌으며 이러한 짧은 디스패치를 실행하는 데 1 ~ 2 사이클 만 걸렸습니다. 반면에 AMD는 추가 웨이브 프론트를위한 공간이 있음에도 불구하고 다음 사이클을 위해 4 사이클을 기다려야했습니다.
각 벡터는 여러 데이터 세트에서 동일한 명령어를 수행 할 수 있습니다. 벡터 스케줄링은 항상 여러 항목에서 실행되는 하나의 명령이 있다는 것을 기반으로 작동합니다. 사용 가능한 세트가 하나 또는 두 개뿐이면 나머지 슬롯은 해당주기 동안 유휴 상태가됩니다.
SIMD

GCN 컴퓨팅 유닛
요약하자면 다른 많은 SIMD 설계와 마찬가지로 GCN 컴퓨팅 유닛은 한 번에 4 개의 웨이브 프론트에서 작업했으며이를 실행하는 데 4주기가 걸렸습니다. 이상적인 세계에서 이것은 한 파동에 소요되는 유효 시간이 한 사이클임을 의미합니다. 그러나 SIMD가 작동하는 방식 때문에 이것은 사실이 아니었고 CU는 종종 활용률이 낮았습니다.
AMD RDNA : 듀얼 컴퓨팅 아키텍처 및 Wave32
Navi에서 구현 된 RDNA 아키텍처는 32 개의 작업 항목이있는 더 좁은 웨이브 프론트 인 wave32를 사용합니다. 이전 wave64 디자인보다 훨씬 간단하고 효율적입니다. 각 SIMD는 더 넓지 만 컴퓨팅 유닛은 더 좁습니다.

RDNA 이중 컴퓨팅 장치 : 로컬 데이터는 두 CU간에 공유됩니다.
컴퓨팅 유닛이 GCN의 기본 셰이더 유닛 인 경우 RDNA는이를 WGP (Work-Group 프로세서)로 대체합니다. 두 개의 CU가 공유 로컬 데이터와 함께 작동합니다. RDNA SIMD는 GCN의 두 배인 32 개의 셰이더 또는 ALU로 구성됩니다. CU 당 2 개의 SIMD가 있고 듀얼 컴퓨팅 장치에 4 개의 SIMD가 있습니다. CU의 총 스트림 프로세서 수는 여전히 64 개이지만 더 넓은 2 개의 SIMD (4 개가 아님)에 분산되어 있습니다. 아래의 지침 다이어그램 당 4 개 사이클 대 1 개 사이클을 참조하십시오 .
RDNA SIMD는 GCN의 두 배인 32 개의 셰이더 또는 ALU로 구성됩니다. CU 당 2 개의 SIMD가 있고 듀얼 컴퓨팅 장치에 4 개의 SIMD가 있습니다. CU의 총 스트림 프로세서 수는 여전히 64 개이지만 더 넓은 2 개의 SIMD (4 개가 아님)에 분산되어 있습니다.

이 배열은 하나의 클록 사이클에서 하나의 전체 웨이브 프론트를 실행하여 병목 현상을 줄이고 IPC를 4 배까지 높일 수 있습니다. 웨이브 프론트를 4 배 빠르게 완료하면 레지스터와 캐시가 훨씬 더 빠르게 해제되어 전체적으로 더 많은 명령을 예약 할 수 있습니다. 또한 wave32는 수 레지스터의 절반을 wave64로 사용하여 회로 복잡성과 비용도 줄입니다.

더 좁은 파면을 수용하기 위해 벡터 레지스터 파일도 재구성되었습니다. 이제 각 벡터 범용 레지스터 (vGPR)에는 32 비트 너비 (FP32 용) 인 32 개의 레인이 포함되고 SIMD에는 총 1,024 개의 vGPR이 포함됩니다. 다시 말해서 GCN에서와 같이 레지스터 수의 4 배입니다.
전반적으로 더 좁은 wave32 모드는 IPC와 총 동시 웨이브 프론트 수를 개선하여 처리량을 증가시켜 성능과 효율성을 크게 향상시킵니다.

이전 GCN 명령어 세트와의 호환성을 보장하기 위해 Navi의 RDNA SIMD는 혼합 정밀도 컴퓨팅을 지원합니다. 따라서 새로운 Navi GPU는 게임 워크로드 (FP32)뿐만 아니라 과학 (FP64) 및 AI (FP16) 애플리케이션에도 적합합니다. RDNA SIMD는 wave32 모드에서 2 배, wave64 모드에서 44 %의 지연 시간을 개선합니다.

4주기 vs 명령 당 1주기
비동기 컴퓨팅 터널링
GCN 아키텍처의 주요 하이라이트 중 하나는 NVIDIA가 그래픽 카드에 통합하기 전에 비동기식 Compute Engine 방식을 사용한 것입니다. RDNA는 이러한 기능을 유지하고 두 배로 늘어납니다.

명령 프로세서는 API의 명령을 처리 한 다음 각 파이프 라인에 실행합니다. 그래픽 명령 프로세서는 그래픽 파이프 라인 (셰이더 및 고정 기능 하드웨어)을 관리하고 4 개의 비동기 Compute Engine (ACE)이 컴퓨팅을 처리합니다. Navi 10 다이 (RX 5700 XT)에는 그래픽 명령 프로세서 1 개와 ACE 4 개가 있습니다. 각 ACE에는 고유 한 명령 스트림이 있으며 GCP에는 모든 셰이더 유형 (도메인, 정점, 픽셀, 래스터 등)에 대한 개별 스트림이 있습니다.
GCN에서 명령 프로세서는 그래픽보다 컴퓨팅의 우선 순위를 지정할 수 있습니다. RDNA 아키텍처에서 GPU는 우선 순위가 높은 컴퓨팅 작업에 모든 리소스를 사용하여 그래픽 파이프 라인을 완전히 중단 할 수 있습니다.

RDNA 아키텍처는 비동기 컴퓨팅 터널링이라는 새로운 기능을 도입하여 명령 수준에서 병렬 처리를 개선합니다. GCN과 최신 Navi GPU는 모두 비동기 컴퓨팅 (그래픽 및 컴퓨팅 파이프 라인의 동시 실행)을 지원하지만 RDNA는 한 단계 더 나아갑니다. 한 작업 (그래픽 또는 컴퓨팅)이 다른 작업보다 지연 시간에 훨씬 더 민감 해지는 경우 Navi는 후자를 완전히 중단 할 수 있습니다.
GCN 기반 Vega 설계에서 명령 프로세서는 그래픽보다 컴퓨팅의 우선 순위를 지정하고 셰이더에 더 적은 시간을 소비 할 수 있습니다. RDNA 아키텍처에서 GPU는 우선 순위가 높은 컴퓨팅 작업에 모든 리소스를 사용하여 그래픽 파이프 라인을 완전히 중단 할 수 있습니다. 이는 가상 현실과 같이 대기 시간에 가장 민감한 워크로드에서 성능을 크게 향상시킵니다.
제어 흐름을위한 스칼라 실행
AMD의 GCN 및 RDNA 아키텍처에서 대부분의 계산은 본질적으로 벡터 인 SIMD에 의해 수행됩니다. 여러 데이터 유형에 대해 단일 명령을 수행합니다 (주기 당 SIMD 당 32 개의 INT / 32 FP가 동시에 실행 됨). 그러나 각 CU에도 스칼라 단위가 있습니다. RDNA 1의 각 컴퓨팅 유닛은 사이클 당 4 개의 명령어, 2 개의 스칼라, 2 개의 벡터를 시작 (디스패치) 할 수 있습니다. RDNA1 WGP 내에서 총 처리량은 클록 당 128 개의 벡터와 4 개의 스칼라입니다. 4 개의 SIMD 각각은 그 수치에 똑같이 기여합니다.

각 SIMD에는 20 개의 웨이브 프론트 각각에 대해 128 개의 항목이있는 10KB 스칼라 레지스터 파일이 있습니다. 레지스터는 폭이 32 비트이며 패킹 된 16 비트 데이터 (정수 또는 부동 소수점)를 보유 할 수 있으며 인접 레지스터 쌍은 64 비트 데이터를 보유합니다. 스칼라는로드 / 저장 장치의 주소 생성에 사용되며 SIMD 제어 흐름을 관리합니다.
웨이브 프론트가 시작되면 스칼라 레지스터 파일은 상수를 전달하기 위해 최대 32 개의 사용자 레지스터를 미리로드하여 명시 적로드 명령을 피하고 웨이브 프론트의 시작 시간을 줄일 수 있습니다.

16KB 후기 입 스칼라 캐시는 4 방향 연관성이며 각각 64B 인 128 개 캐시 라인의 두 뱅크로 구성됩니다. 각 뱅크는 전체 캐시 라인을 읽을 수 있으며 캐시는 클록 당 16B를 각 SIMD의 스칼라 레지스터 파일에 전달할 수 있습니다. 그래픽 셰이더의 경우 스칼라 캐시는 일반적으로 상수 및 작업 항목 독립 변수를 저장하는 데 사용됩니다.
캐시 : L0 및 공유 L1
이전 GCN 및 라이벌 NVIDIA GPU는 두 가지 수준의 캐시에 의존하지만 RDNA는 Navi GPU에 세 번째 L1 캐시를 추가합니다. L0 캐시가 DCU 전용 인 경우 L1 캐시는 이중 컴퓨팅 장치 그룹에서 공유됩니다. 이를 통해 비용, 대기 시간 및 전력 소비를 줄일 수 있습니다. L2 캐시의로드를 줄입니다. GCN에서 코어 당 L1 캐시의 모든 캐시 미스는 L2 캐시에서 처리되었습니다. RDNA에서 새로운 L1 캐시는 각 셰이더 배열 내의 모든 캐싱 기능을 중앙 집중화합니다.
L0 캐시는 DCU 전용이지만 L1 캐시는 이중 컴퓨팅 장치 그룹에서 공유됩니다.

L0 캐시에서 발생하는 모든 캐시 누락은 L1 캐시로 전달됩니다. 여기에는 픽셀 캐시 외에도 명령어, 스칼라 및 벡터 캐시의 모든 데이터가 포함됩니다. L1은 읽기 전용 캐시이며 각각 4 개의 뱅크로 구성되어 총 128KB가됩니다. 16-way set-associative 캐시 메모리입니다. L1 캐시는 L2에 의해 지원됩니다. L1에 대한 쓰기는 무효화되고 L2 또는 메모리에 복사됩니다.

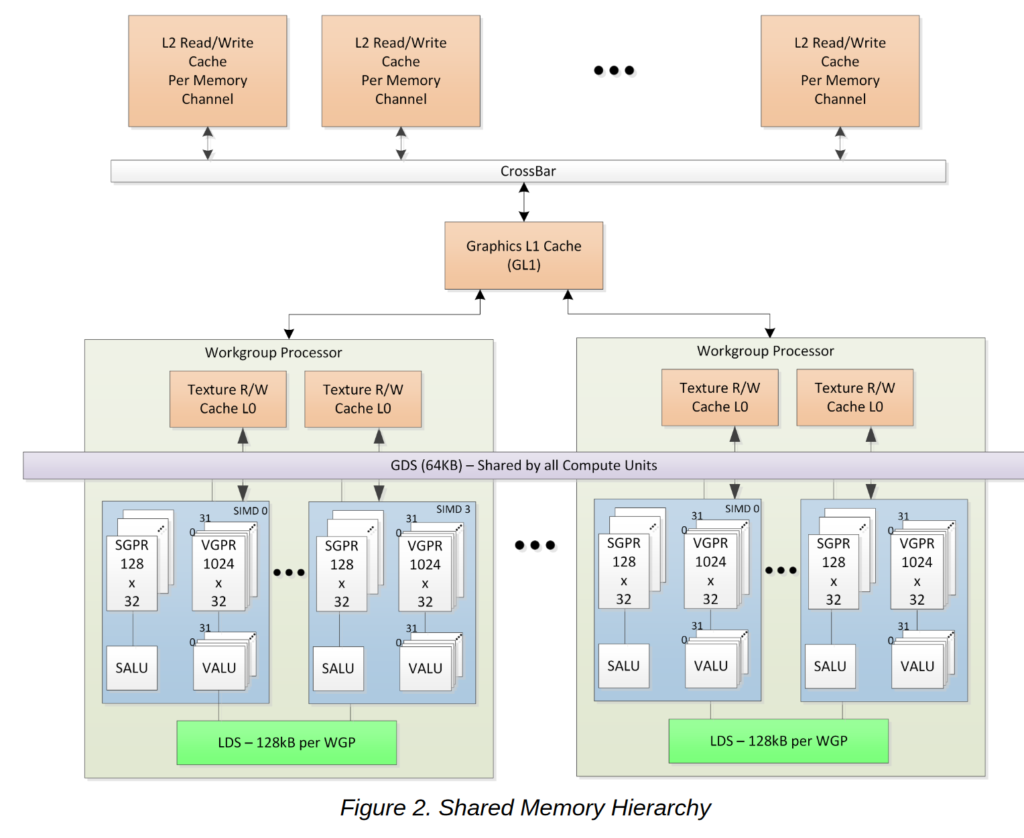
L1 그래픽 캐시는 4 개의 WGP 또는 셰이더 어레이간에 공유됩니다.
L1 캐시 컨트롤러는 메모리 요청을 조정하고 클럭 사이클 당 4 개를 각 L1 뱅크에 하나씩 전달합니다. 다른 캐시 메모리와 마찬가지로 L1 미스는 L2 캐시에서 처리됩니다.
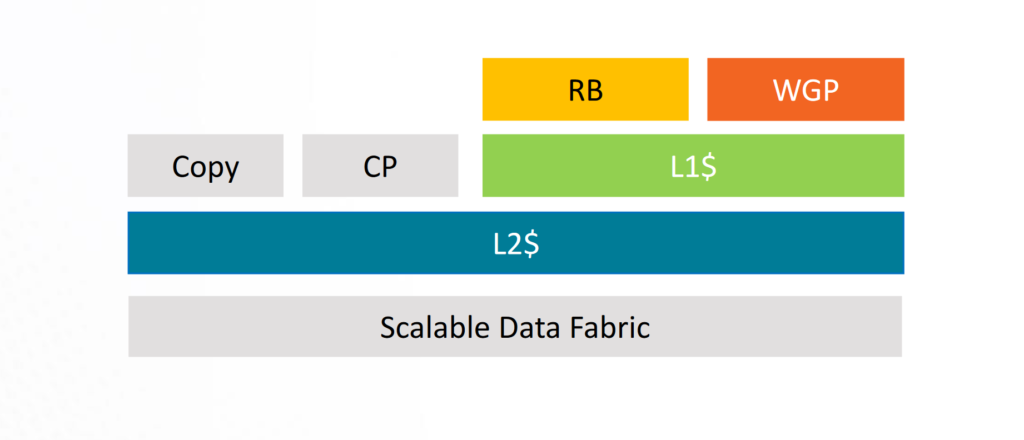
Polaris GPU에서는 컴퓨팅 유닛 만 L2 캐시의 클라이언트였습니다. RB, Copy Engine 및 CP가 메모리에 직접 기록하여 많은 L2 플러시가 발생했습니다. Vega는 L2의 RB 클라이언트도 만들어 L2 플러시를 줄임으로써이 디자인을 개선했습니다. RDNA와 Navi는 복사 엔진을 L2의 클라이언트로 만들어 GCN 파생 제품보다 한발 앞서갑니다. 이로 인해 L2 플러시가 거의 발생하지 않습니다.
듀얼 컴퓨팅 유닛 프런트 엔드
각 컴퓨팅 유닛은 명령어 메모리 가져 오기를 통해 명령어를 가져옵니다. GCN에서는 명령어 캐시가 4 개의 CU간에 공유되었지만 RDNA (Navi)에서는 L0 명령어 캐시가 듀얼 CU의 4 개의 SIMD간에 공유됩니다. 명령어 캐시는 32KB이며 4 방향 세트 연관입니다. L1 캐시와 마찬가지로, 각각 64 바이트 길이의 128 개 캐시 라인의 4 개 뱅크로 구성됩니다.
GCN에서는 명령어 캐시가 4 개의 CU간에 공유되었지만 RDNA (Navi)에서는 L0 명령어 캐시가 듀얼 CU의 4 개의 SIMD간에 공유됩니다.

가져온 명령은 웨이브 프론트 컨트롤러에 저장됩니다. 각 SIMD에는 별도의 명령 포인터와 20 개 항목의 웨이브 프론트 컨트롤러가있어 듀얼 컴퓨팅 유닛 당 총 80 개의 웨이브 프론트가 있습니다. Wavefront는 작업 그룹 또는 커널과 다를 수 있습니다. 더 많은 수의 웨이브 프론트를 가져올 수 있지만 이중 컴퓨팅 장치는 동시에 두 개의 wave32 작업 그룹에서만 작동합니다.

이미 언급했듯이 GCN이 4주기마다 한 번씩 명령을 요청한 경우 Navi는주기마다 (주기 당 2-4 인치) 명령을 수행합니다. 그 후 RDNA 기반 Navi GPU의 각 SIMD는 매 사이클마다 명령을 디코딩하고 발행 할 수 있으므로 처리량을 높이고 GCN에 비해 지연 시간을 4 배 줄일 수 있습니다.

새로운 wave32 모드를 수용하기 위해 각 RDNA SIMD의 캐시 및 메모리 파이프 라인도 개선되었습니다. 파이프 라인 너비는 GCN 기반 Vega GPU에 비해 두 배가되었습니다. 모든 SIMD에는 웨이브 프론트의 작업 항목에 대한 주소를 ALU 또는 vGPR (벡터 범용 레지스터)로 직접 전송할 수있는 32 와이드 요청 버스가 있습니다.
한 쌍의 SIMD는 요청 및 리턴 버스를 공유하지만 단일 SIMD는 클럭 당 128B 캐시 라인의 두 청크를 수신 할 수 있습니다. 하나는 LDS (Load-Store)에서, 다른 하나는 Vector L0 캐시에서 제공합니다.
렌더 백 엔드 (RB) 및 텍스처 단위
RDNA 기반 Navi GPU의 최종 고정 기능 그래픽 단계는 깊이, 스텐실 및 알파 테스트를 수행하고 앤티 앨리어싱 및 기타 최종 테스트를 위해 픽셀을 혼합하는 RB (렌더링 백엔드)입니다. 셰이더 배열의 각 RB는 클럭 당 4 개의 출력 픽셀 속도로 픽셀을 테스트, 샘플링 및 혼합 할 수 있습니다. 여기에서 RDNA 아키텍처의 주요 개선 사항은 RB가 그래픽 L1 캐시를 통해 데이터에 액세스한다는 것입니다. 이는 L2 캐시에 대한 부담을 줄이고 더 적은 데이터를 이동하여 전력을 절약합니다. GCN에서 RB가 메모리에 직접 데이터를 쓴 다음 L2 캐시를 통해 Vega에 데이터를 쓴 것을 기억하십시오.

텍스처 유닛은 RDNA와 Navi를 통해 상당한 향상을 얻었습니다. 로드 및 저장 처리 속도는 GCN에 비해 여러 배 빠르므로 GPU가로드 및 저장을 통해 최대 대역폭에 더 쉽게 도달 할 수 있습니다.

RDNA 대 GCN : ALU 활용 비교

GCN에 비해 SIMD 및 Navi의 WGP (RDNA)를 포화시키는 것이 훨씬 쉽습니다. 하나의 WGP (2 CU)는 100 % ALU 사용률에 도달하기 위해 128 개의 스레드 (4 개의 SIMD * 32 개 항목) 만 필요합니다. 반면 GCN은 100 % 사용률에 도달하기 위해 512 개의 스레드가 필요했습니다 (2 CU * 4 SIMD * 65 항목). 4 배나됩니다!
비디오 인코딩 및 디코딩
NVIDIA의 Turing 인코더와 마찬가지로 Navi GPU는 비디오 인코딩 및 디코딩을위한 특수 엔진도 갖추고 있습니다.

Navi 10 (RX 5600 & 5700)에서는 Vega와 달리 비디오 엔진이 VP9 디코딩을 지원합니다. H.264 스트림은 1080p의 경우 600 프레임 / 초, 150fps의 4K로 디코딩 할 수 있습니다. 동시에 약 절반의 속도로 인코딩 할 수 있습니다. 즉, 360fps에서 1080p, 90fps에서 4K입니다. 8K 디코딩은 HVEC 및 VP9 모두에 대해 24fps로 사용할 수 있습니다.
7nm 공정 및 GDDR6 메모리 표준
7nm 노드와 GDDR6 메모리는 종종 새로운 아키텍처의 일부로 광고되지만 이들은 타사 기술이며 정확히 RDNA 마이크로 아키텍처의 일부가 아닙니다. 그러나 GPU는 이러한 기술을 최대한 활용하도록 최적화되어 있습니다.

그러나 TSMC의 7nm 노드는 이전 GCN 설계, 즉 Polaris 및 Vega를 지원하는 이전 14nm 프로세스에 비해 와트 당 성능을 크게 향상시킵니다. 면적당 성능이 2.3 배 향상되고 와트 당 성능이 1.5 배 향상됩니다.

대역폭을 최대화하기 위해 가능한 경우 데이터 압축이 적극적으로 추가되었습니다. GCN과 Navi는 RB에서 압축 된 읽기 및 쓰기 만 수행했지만 Navi는 후자를 CU로 확장하고 현재 대기열에서도 구현합니다.

이제 RB 외에 WGP (CU)와 L2 캐시 사이에 압축기 모듈이 있습니다. Vega에는 전자가 없었고 데이터 압축은 L2에서 읽기로 제한되었습니다.
결론
보시다시피 RDNA와 Navi는 Radeon 디자인을 정확히 재창조하지는 않지만 주로 수정합니다. 파이프 라인 병목 현상이 제거되고 지연 시간이 감소했으며 이제 모든 SIMD가 더 넓고 빨라졌습니다. 셰이더 엔진 당 더 많은 렌더 백엔드가 있으며, 세 가지 수준의 통합 캐시가 있으며 이는 이전 Vega GPU보다 크게 향상되었습니다. RDNA 2가 기존 Navi GPU와 얼마나 다른지 보는 것은 흥미로울 것입니다. 솔직히 말하자면 급진적 인 변화는 없을 것 같습니다. 레이 트레이싱 가속 또는 업 스케일링을위한 전용 코어가있을 수 있습니다. AMD가 작업해야하는 것은 소프트웨어와 드라이버입니다.
Difference Between AMD RDNA vs GCN GPU Architectures: How Radeon Caught up to NVIDIA | Hardware Times
With the launch of the Big Navi graphics cards, AMD has finally returned to the high-end GPU space with a bang. While the RDNA 2 design is largely similar to RDNA 1 in terms of the compute and graphics pipelines, there are some changes that have allowed th
www.hardwaretimes.com
'정보 Tips > IT Hardware' 카테고리의 다른 글
| 아이패드 프로 5세대 mini led 블루밍 이슈 (0) | 2021.05.28 |
|---|---|
| 애플 트루 톤에 대해 (0) | 2021.05.28 |
| 애플 M1 게이밍 그래픽 성능 (0) | 2021.05.24 |
| AMD Radeon GPU 에서 Ray-Tracing (RTX) 활성화 (0) | 2021.05.21 |
| NAS의 개념 NAS 활용법 (0) | 2021.05.16 |
| 삼성 갤럭시 버즈 프로 외이도염 문제 (0) | 2021.05.06 |
| 메모리 램 싱글 랭크 vs 듀얼 랭크 (0) | 2021.05.04 |
| 라이젠 오버클럭 CTR 사용법 (0) | 2021.04.28 |




