그래픽 카드는 다단계 캐시 계층을 특징으로 수년에 걸쳐 개발되었습니다. 이러한 수준의 캐시는 많은 애플리케이션에서 GPU의 성능을 저하시키고 증가하는 문제인 메모리와 컴퓨팅 사이의 간격을 메우기 위해 설계되었습니다. AMD 및 NVIDIA와 같은 다른 GPU 공급업체는 아키텍처에 따라 레지스터 파일, L1 및 L2 캐시의 크기가 다릅니다. 예를 들어, NVIDIA A100 GPU의 L2 캐시 양은 40MB로 이전 세대 V100에 비해 7배 더 큽니다. 이는 새로운 애플리케이션에 더 큰 캐시 크기가 필요한지 여부를 보여주며, 요구 사항을 충족하기 위해 계속 증가하고 있습니다.


오늘, 우리는 Chips and Cheese에서 나온 흥미로운 보고서를 가지고 있습니다. 이 웹 사이트는 AMD의 RDNA 2 및 NVIDIA의 Ampere와 같은 최신 카드 세대의 GPU 메모리 지연 시간을 측정하기로 결정했습니다. OpenCL에서 간단한 포인터 추적 테스트를 사용하면 흥미로운 결과를 얻을 수 있습니다. RDNA 2 캐시는 빠르고 방대합니다. Ampere에 비해 캐시 지연 시간은 훨씬 낮지만 VRAM 지연 시간은 거의 같습니다. NVIDIA는 L1과 L2로 구성된 2 단계 캐시 시스템을 사용하는데, 이는 다소 느린 솔루션으로 보입니다. L1 캐시를 보유하는 Ampere의 SM에서 외부 L2로 들어오는 데이터는 100ns 이상의 지연 시간을 차지합니다.
반면, AMD에는 3단계 캐시 시스템이 있습니다. RDNA 2 설계를 보완하기 위한 L0, L1 및 L2 캐시 레벨이 있습니다. L0과 L2 사이의 지연 시간은 L1이 있더라도 66ns에 불과합니다. 본질적으로 L3 캐시인 Infinity Cache는 추가 지연 시간을 20ns만 추가하여 NVIDIA의 캐시 솔루션에 비해 훨씬 더 빠릅니다. NVIDIA의 GA102 대용량 다이는 L2 캐시가 회전하는데 많은 사이클이 소요되기 때문에 큰 문제를 나타내는 것 같습니다.
GPU 메모리 대기 시간 측정
우리는 CPU 캐시와 메모리 대기 시간을 측정하는 데 익숙해 졌는데 GPU에도 똑같이 하지 않는 이유는 무엇입니까? CPU와 마찬가지로 GPU는 컴퓨팅과 메모리 성능 간의 증가하는 격차를 해결하기 위해 다단계 캐시 계층을 사용하도록 진화했습니다. CPU와 마찬가지로 OpenCL에서 포인터 추적 벤치 마크를 사용하여 캐시 및 메모리 대기 시간을 측정할 수 있습니다.
더 이상 고민하지 않고 Chips and Cheese의 작업중인 GPU 메모리 지연 테스트의 첫 번째에 오신 것을 환영합니다.
암페어 및 RDNA 2
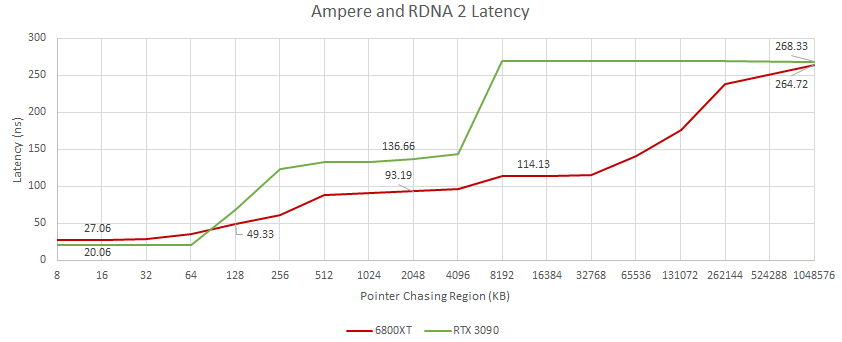
RTX 3090 및 RX 6800XT에서 포인터 추적 지연 테스트 결과
RDNA 2의 캐시는 빠르며 많은 양이 있습니다. 암페어에 비해 대기 시간은 모든 수준에서 낮습니다. Infinity Cache는 L2 적중 시 약 20ns 만 추가하며 Ampere의 L2보다 지연 시간이 더 짧습니다. 놀랍게도 RDNA 2의 VRAM 대기 시간은 RDNA 2가 메모리로 가는 도중에 두 가지 수준의 캐시를 더 확인하더라도 Ampere와 거의 같습니다.
반대로 Nvidia는 캐시 수준이 2 개 뿐이고 L2 지연 시간이 긴 기존 GPU 메모리 하위 시스템을 고수합니다. Ampere의 SM 전용 L1에서 L2로 이동하는 데는 100ns 이상이 걸립니다. RDNA의 L2는 L1 캐시가 있더라도 L0에서 ~ 66ns 떨어져 있습니다. GA102의 거대한 다이를 돌아다니는 데는 많은 주기가 걸리는 것 같습니다.
이것은 낮은 해상도에서 AMD의 뛰어난 성능을 설명 할 수 있습니다. RDNA 2의 낮은 대기 시간 L2 및 L3 캐시는 점유가 너무 낮아 대기 시간을 숨길 수없는 작은 워크로드에서 이점을 제공할 수 있습니다. Nvidia의 Ampere 칩은 빛을 발하기 위해 더 많은 병렬 처리가 필요합니다.
CPU vs GPU : 대학살
CPU는 가능한 한 빨리 직렬 워크로드를 실행하도록 설계되었습니다. GPU는 대규모 병렬로드를 실행하도록 구축되었습니다. 테스트는 OpenCL로 작성되었으므로 수정하지 않고 CPU에서 실행할 수 있습니다.
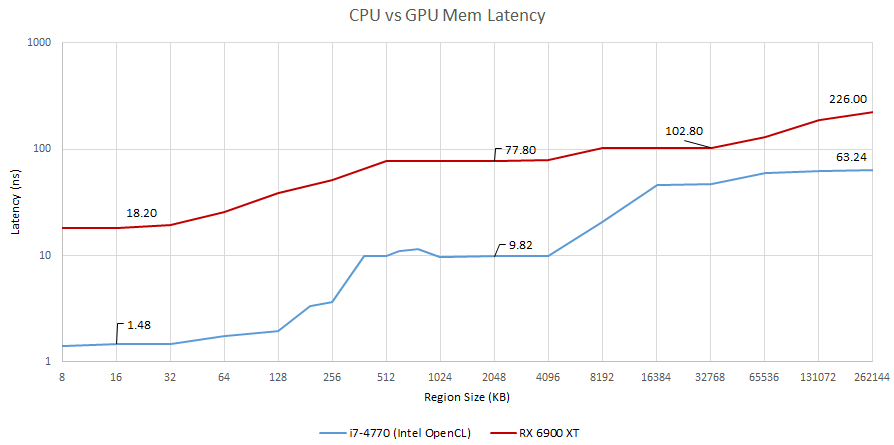
Intel의 OpenCL 런타임을 사용하여 CPU에서 테스트를 실행 한 결과.
Haswell의 캐시 및 DRAM 대기 시간이 너무 낮아 대기 시간을 대수 단위로 설정해야 했습니다. 그렇지 않으면 RDNA 2의 수치 아래에 평평한 선처럼 보일 것입니다. DDR3-1600 CL9를 사용하는 i7-4770은 63ns에서 메모리로 왕복할 수 있는 반면, GDDR6을 사용하는 6900 XT는 동일한 작업을 수행하는 데 226ns가 걸립니다.
하지만 다른 관점에서 보면 GDDR6 대기 시간 자체는 그렇게 나쁘지 않습니다. CPU 또는 GPU는 메모리로 이동하기 전에 캐시를 확인하고 누락을 확인해야합니다. 따라서 메모리로 가는 시간이 마지막 수준의 캐시 적중을 차지하는 시간을 보는 것만으로도 메모리 대기 시간에 대한보다 "원시"보기를 얻을 수 있습니다. 마지막 수준 캐시 적중과 실패 사이의 델타는 Haswell에서 53.42ns, RDNA2에서 123.2ns입니다.
흥미로운 사고 실험으로 GDDR6 메모리 컨트롤러를 가능한 한 L3에 가깝게 배치 한 가상의 Haswell은 약 133ns에 도달 할 수 있습니다. 클라이언트 CPU의 경우 높지만 서버 메모리 대기 시간보다 그리 높지는 않습니다.
이 섹션과 아래는 루프 언 롤링이있는 최신 버전을 사용하고 있기 때문에 위의 섹션과 비교할 수 없으며 Ampere에서 두 번째 실행을 얻을 수 없습니다. 그러나 Pascal과 같은 구형 Nvidia GPU는 10 배 풀린 루프에서 개선되지 않았으므로 Ampere의 결과가 변경되지 않을 가능성이 높습니다.
구형 Nvidia GPU
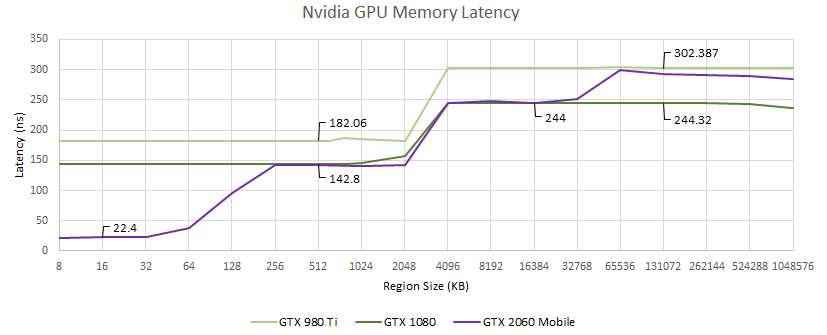
Maxwell, Pascal 및 Turing에 대한 메모리 대기 시간 (Turing에 대한 깨끗한 실행은 아니지만 일반적인 그림을 얻음)
Maxwell과 Pascal은 대체로 유사하며 GTX 980 Ti는 더 큰 다이와 더 낮은 클럭으로 인해 어려움을 겪을 가능성이 있습니다. 데이터는 칩 주위를 돌아다니는 데 더 오래 걸립니다. Nvidia는 OpenCL이 두 아키텍처에서 L1 텍스처 캐시를 사용하도록 허용하지 않으므로 안타깝게도 가장 먼저 보게 되는 것은 L2 대기 시간입니다.
Turing은 Ampere처럼 보이기 시작합니다. 상대적으로 낮은 지연 시간 L1, L2, 마지막으로 메모리가 있습니다. L2 지연 시간은 대략 Pascal과 비슷합니다. 원시 메모리 대기 시간은 최대 32MB까지 비슷합니다. 나중에 더 높지만 소음을 배제 할 수는 없습니다.
AMD GPU 세대 비교

Terascale 2, 3, GCN 및 RDNA 2에 대한 지연 시간 플롯
32KB 미만의 Terascale의 낮은 지연 시간에 대한 설명이 없습니다. AMD는 Terascale에 8KB L1 데이터 캐시가 있으며 내 결과가 일치하지 않는다고 말합니다. 테스트는 일종의 정점 재사용 캐시에 도달 할 수 있습니다 (메모리 로드가 정점 가져오기 절로 컴파일되기 때문에).
GCN 및 RDNA 2는 예상대로 보입니다. 그리고 시간이 지남에 따라 모든 수준에서 AMD의 지연 시간이 낮아지는 것을 보는 것은 매우 흥미 롭습니다.
Measuring GPU Memory Latency
We’ve gotten used to measuring CPU cache and memory latencies, so why not do the same to GPUs? Like CPUs, GPUs have evolved to use multi-level cache hierarchies to address the growing gap between c…
chipsandcheese.com
'정보 Tips > IT Hardware' 카테고리의 다른 글
| amd radeon rx 5700 모어 파워툴 사용법 (0) | 2021.04.25 |
|---|---|
| navi 10 amd radeon rx 5000번대 성능 향상 방법 (0) | 2021.04.25 |
| 모니터 패널 잔상 비교 (0) | 2021.04.25 |
| 빅나비 amd 라데온 rx 6800 모어 파워 툴 언더볼팅 (0) | 2021.04.23 |
| 베이퍼 챔버 Vapor Chamber (0) | 2021.04.19 |
| pcie 1.1 vs pcie 2.0 vs pcie 3.0 vs pcie 4.0 게임 성능 비교 벤치마크 (0) | 2021.04.18 |
| pcie 3.0 vs pcie 4.0 게임성능 비교 벤치마크 (0) | 2021.04.18 |
| cpu gpu vga 쿨러 장착 방향에 따른 온도 차이 수직 vs 수평 (1) | 2021.04.18 |




